
Over the years, Google has seemingly established a pattern in how it interacts with the web. The search engine provides structured data formats and tools that allow us to supply information to Google. Think: meta tags, schema markup, the disavow tool and more.
Google then consumes and learns from this structured data deployed across the web. Once sufficient learnings are extracted, Google then retires or de-emphasizes these structured data formats, making them less impactful or obsolete.
This cyclical process of giving structured data capabilities, consuming the information, learning from it and then removing or diminishing those capabilities seems to be a core part of Google’s strategy.
It allows the search engine to temporarily empower SEOs and brands as a means to an end – extracting data to improve its algorithms and continually improve its understanding of the web.
This article explores this “give and take” pattern through several examples.
Google’s pattern of ‘give and take’
The pattern can be divided into four stages:
- Structure: Google provides structural ways to interact with search snippets or its ranking algorithms. For example, in the past, meta keywords could tell Google which keywords were relevant to a given webpage.
- Consume: Google collects data from the web by crawling websites. This step is important. Without consuming data from the web, Google has nothing to learn from.
- Learn: Google then leverages fresh crawl data, after its recommended structures are implemented. What were the reactions to Google’s proposed tools or snippets of code? Were these useful changes, or were they abused? Google can now confidently make changes to its ranking algorithms.
- Retire: Once Google has learned what they can, there’s no reason to rely on us to feed them structured information. Leaving such inbound data pipes intact will invariably lead to abuse over time, so the search engine must learn to survive without them. The suggested structure from Google is retired in many (though not all) instances.
The race is for the search engine to learn from webmasters’ interactions with Google’s suggested structure before they can learn to manipulate it. Google usually wins this race.
It doesn’t mean no one can leverage new structural items before Google discards them. It simply means that Google usually discards such items before illegitimate manipulations become widespread.
Give and take examples
1. Metadata
In the past, meta keywords and meta descriptions played crucial roles within Google’s ranking algorithms. The initial support for meta keywords within search engines actually predates Google’s founding in 1998.
Deploying meta keywords was a way for a webpage to tell a search engine the terms for which the page should be findable. However, such a direct and useful bit of code was quickly abused.
Many webmasters injected thousands of keywords per page in the interest of getting more search traffic than was fair. It quickly led to the rise of low-quality websites filled with ads that unfairly converted acquired traffic into advertising income.
In 2009, Google confirmed what many had suspected for years. Google stated:
“At least for Google’s web search results currently (September 2009), the answer is no. Google doesn’t use the keywords meta tag in our web search ranking.”

Another example is the meta description, a snippet of code that Google supported since its early days. Meta descriptions were used as the snippet text under a link in Google search results.
As Google improved, it started ignoring meta descriptions in certain situations. This is because users might discover a webpage through various Google keywords.
If a webpage discusses multiple topics and a user searches for a term related to topic 3, showing a snippet with a description of topics 1 or 2 would not be helpful.
Therefore, Google began rewriting search snippets based on user search intent, sometimes ignoring a page’s static meta description.
In recent times, Google has shortened search snippets and even confirmed that they mostly examine a page’s primary content when generating descriptive snippets.
2. Schema and structured data
Google introduced support schema (a form of structured data) in 2009.
Initially, it pushed the “microformats” style of schema, where individual elements had to be marked up within the HTML to feed structured or contextual information to Google.
In terms of concept, this actually isn’t too far removed from the thinking behind HTML meta tags. Surprisingly, a new coding syntax was adopted instead of just using meta tags more extensively.
For example, the idea of schema markup was initially (and largely remains) to supply additional contextual information concerning data or code that is already deployed – which is similar to the definition of metadata:
- “Information that describes other information in order to help you understand or use it.”
Both schema and metadata attempt to achieve this same goal. Information that describes other existing information to help the user leverage such information. However, the detail and structural hierarchy of schema (in the end) made it far more scalable and effective.
Today, Google still uses schema for contextual awareness and detail concerning various web entities (e.g., webpages, organizations, reviews, videos, products – the list goes on).
That said, Google initially allowed schema to alter the visuals of a page’s search listings with a great degree of control. You could easily add star ratings to your pages for Google’s search results, making them stand out (visually) against competing web results.
As usual, some began abusing these powers to outperform less SEO-aware competitors.
In February 2014, Google started talking about penalties for rich snippet spam. This was when people misused schema to make their search results look better than others, even though the information behind them was wrong. For example, a site without reviews purports a 5-star aggregate review rating (clearly false).
Fast-forward to 2024, and while still situationally useful, schema is not as powerful as it once was. Delivery is easier, thanks to Google’s JSON-LD preference. However, schema no longer has the absolute power to control the visuals of a search listing.
3. Rel=Prev / Next
Rel=”prev” and rel=”next” were two HTML attributes Google suggested in 2011. The idea was to help Google develop more contextual awareness of how certain types of paginated addresses were interrelated:
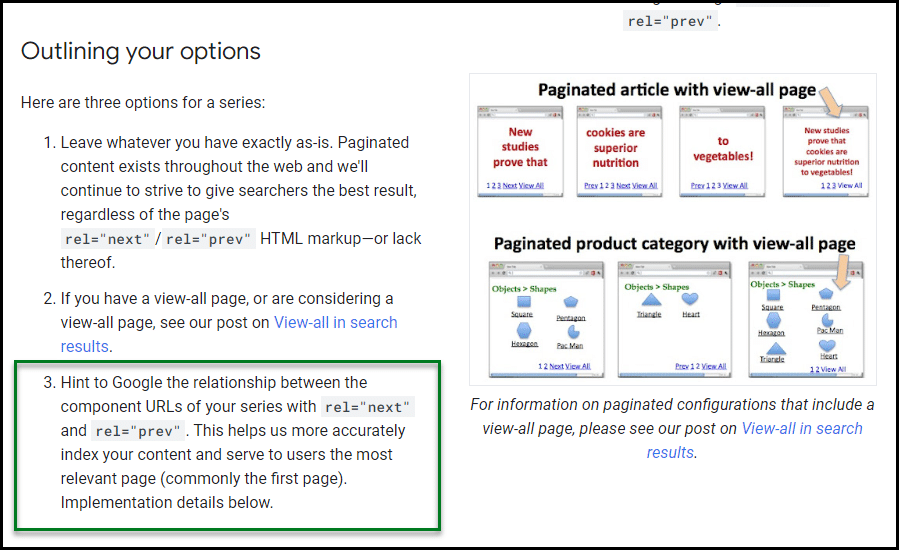
Eight years later, Google announced they no longer supported it. They also said they hadn’t supported this kind of coding for a while, suggesting support ended around 2016, just five years after the suggestions were first made.
Many were understandably annoyed because the tags were fiddly to implement, often requiring actual web developers to re-code aspects of website themes.
Increasingly, it seemed as if Google would suggest complex code changes in one moment only to ditch them the next. In reality, it is likely that Google had simply learned all it needed from the rel=prev / next experiment.
4. Disavow tool
In October 2012, the web buzzed with news of Google’s new Disavow links tool.
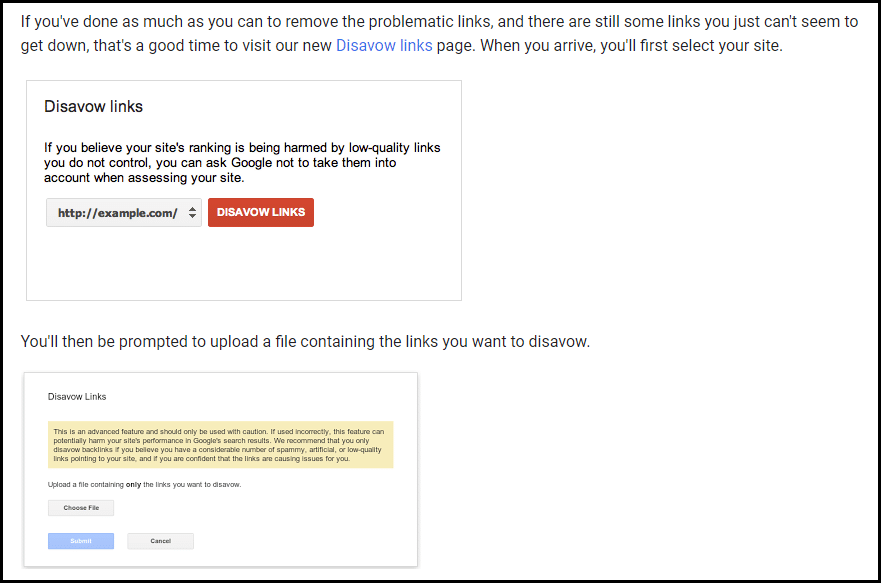
In April 2012, Google released the Penguin update, which caused the web to be in turmoil. The update targeted spammy off-site activity (link building) heavily, and many websites saw manual action notices appear within the Search Console (then named Webmaster Tools).
Using the Disavow tool, you could upload lists of linking pages or domains they would like to exclude from Google’s ranking algorithms. If these uploaded links largely agreed with Google’s own internal assessment of the backlink profile, the active manual penalty may then have been lifted.
This would give back a “fair” amount of Google traffic to their site, though obviously, with part of their backlink profile now “disavowed” – post-penalty traffic was usually lower than pre-penalty traffic.
As such, the SEO community had a relatively low opinion of the tool. Usually, a complete backlink removal or disavow project was necessary. Having less traffic after the penalty was better than having no traffic at all.
Disavow projects haven’t been necessary for years. Google now says that anyone still offering this service is using outdated practices.
In recent years, Google’s John Mueller has been extremely critical of those selling “disavow” or “toxic links” work. It seems as if Google no longer wants us to use this tool; certainly, they do not advise us on its usage (and haven’t in many years).
Dig deeper. Toxic links and disavows: A comprehensive SEO guide
Unraveling Google’s give-and-take relationship with the web
Google provides tools or code snippets for SEOs to manipulate its search results in minor ways. Once Google gains insights from these deployments, such features are frequently phased out. Google grants us a limited amount of temporary control to facilitate its long-term learning and adaptation.
Does this make these small, temporary releases from Google useless? There are two ways of looking at this:
- Some people will say, “Don’t jump on the bandwagon! These temporary deployments aren’t worth the effort they require.”
- Others will say, “Google gives us temporary opportunities for control, so you need to take advantage before they vanish.”
In truth, there is no right or wrong answer. It depends on your ability to adapt to web changes efficiently.
If you’re comfortable with quick changes, implement what you can and react fast. If your organization lacks the expertise or resources for quick changes, it’s not worth following trends blindly.
I think this ebb and flow of give and take doesn’t necessarily make Google evil or bad. Any business will leverage its unique assets to drive further learning and commercial activity.
In this instance, we are one of Google’s assets. Whether you wish for this relationship (between yourself and Google) to continue is up to you.
You could choose not to cooperate with Google’s temporary power, long-term learning trade deals. However, this may leave you at a competitive disadvantage.